Having a GPU shows the wealth. Today, you should spend thousands of dollars to have a good one. For example, Tesla P100 is 7K, and V100 is 10K USD nowadays. It is funny but GPU owners still suffer from the memory size. Even hundreds of gigabytes memory sticks costs a few of dollars and people use them as key holder. However, GPUs mostly have 16GB and luxurious ones have 32GB memory. In this post, I’ll share some tips and tricks when using GPU and multiprocessing in machine learning projects in Keras and TensorFlow.

We can have greater strength and agility with multiprocessing module of python and GPU similar to 6-armed Spider-Man.
🙋♂️ You may consider to enroll my top-rated machine learning course on Udemy

Reserving a single GPU
If you have multiple GPUs but you need to work on a single GPU, you can mention the specifying GPU number. This starts from 0 to number of GPU count by default. This GPU is reserved to you and all memory of the device is allocated.

- Introducing Nvidia Tesla V100
import os os.environ["CUDA_VISIBLE_DEVICES"]="0" #specific index #os.environ["CUDA_VISIBLE_DEVICES"]="" #to disable gpu
Alternatively, you can specify the GPU name before creating a model. Suppose that you are going to use pre-trained VGG model. You can store 3 different models on 2 GPUs as demonstrated below.
with tf.device('/gpu:0'):
content_model = vgg19.VGG19(input_tensor=base_image
, weights='imagenet', include_top=False)
style_model = vgg19.VGG19(input_tensor=style_reference_image
, weights='imagenet', include_top=False)
with tf.device('/gpu:1'):
generated_model = vgg19.VGG19(input_tensor=combination_image
, weights='vgg_weights.h5', include_top=False)
Central Processing Unit
If working on CPU cores is ok for your case, you might think not to consume GPU memory. In this case, specifying the number of cores for both cpu and gpu is expected.
config = tf.ConfigProto( device_count = {'GPU': 0 , 'CPU': 5} )
sess = tf.Session(config=config)
keras.backend.set_session(sess)
GPU memory is precious
Memory demand enforces you even if you are working on a small sized data. TensorFlow tends to allocate all memory of all GPUs. Consider allocating 16GB memory of 4 different GPUs for a small processing task e.g. building XOR classifier. This is really unfair. It blocks other processes of yourself or different tasks of the others. Everybody including you has to wait until this process ends. You can skip this problem by modifying the session config. Allowing growth handles not to allocate all the memory.
config = tf.ConfigProto() config.gpu_options.allow_growth = True session = tf.Session(config=config) keras.backend.set_session(session)
GpuUtils
I’ve just published a python package – GpuUtils – to analyze and allocate GPUs on your environment.
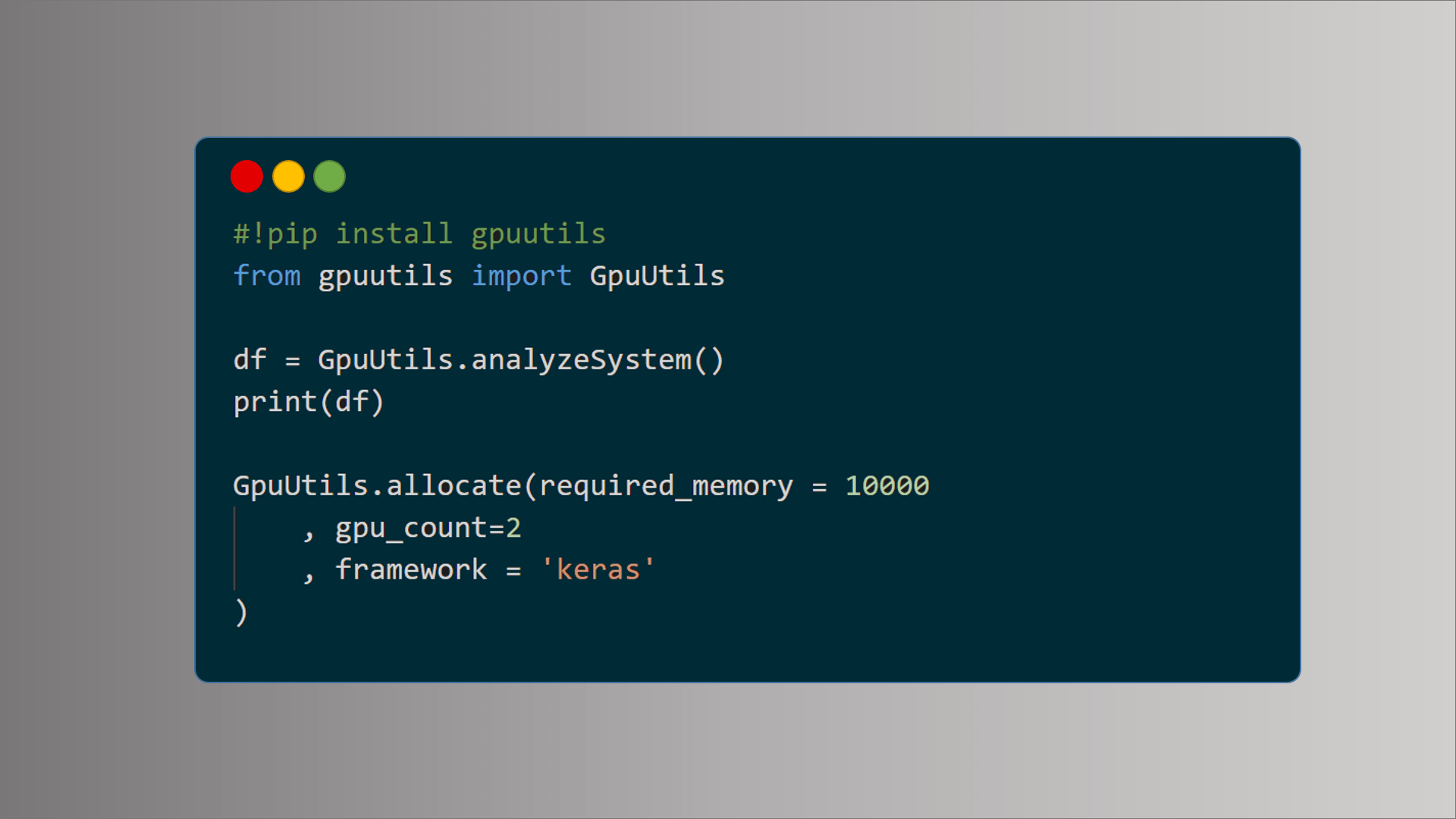
Analysis function returns GPU related information such as total / available memory, utilization percentage as a pandas data frame.

Besides, allocation function find the best GPUs based on your requirement and allocate. Passing framework as an argument avoids greedy approach. In this way, framework will use memory as much as needed.
Multiprocessing
In some cases, you might need to build several machine learning models simultaneously. Building models serially causes significant time loss. Here, Python provides a strong multiprocesing library.
If you run multiprocessing by default configuration, then the first thread allocates all memory and out of memory exception is throwed by the second thread. Using multiprocessing, GPU and allowing GPU memory growth is untouched topic.
from device: CUDA_ERROR_OUT_OF_MEMORY
E tensorflow/core/common_runtime/direct_session.cc:154] Internal: CUDA runtime implicit initialization on GPU:0 failed. Status: out of memory
If you set allowing growth once, you will still face with the following error.
E tensorflow/core/grappler/clusters/utils.cc:81] Failed to get device properties, error code: 3
These problems are solved when you move the session configuration to the dedicated function in training task. But I have a confusing problem this time. Sessions hang even though command seems running. In other words, GPU consumption seems 0% whereas memory allocation still exists. I can solve this problem when I pass the start method of the multiprocessing as spawn in my linux machine. Default configuration is fork in linux whereas spawn in windows.
multiprocessing.set_start_method('spawn', force=True)
It is interesting but the machine confused when it comes to prediction. This time you must not specify the start method. I guess this is because of that each training lasts more than 30 seconds but prediction lasts a second. In my opinion, the machine confuses short task in spawn mode where it confuses longer tasks in fork mode.
Hands-on activity
We feed 10 items into the pool, and multiprocessing library processes these 10 items simultaneously even though there are totally 100 instances. Then, the library will process the remaining 10 items when first pool thread completed.
I realized that if I feed all 100 items to starmap and there are 10 parallel threads, then it would hang. We can avoid hang bug if we set the length of items fed to starmap to the number of parallel threads.
import pandas as pd
import multiprocessing
from multiprocessing import Pool
def train(index, df):
import tensorflow as tf
import keras
from keras.models import Sequential
#------------------------------
#this block enables GPU enabled multiprocessing
core_config = tf.ConfigProto()
core_config.gpu_options.allow_growth = True
session = tf.Session(config=core_config)
keras.backend.set_session(session)
#-------------------------------
#to limit cpu cores in sub program
"""
keras.backend.set_session(
keras.backend.tf.Session(
config=keras.backend.tf.ConfigProto(
intra_op_parallelism_threads=3
, inter_op_parallelism_threads=3)
)
)
"""
#-------------------------------
#prepare input and output values
df = df.drop(columns=['index'])
data = df.drop(columns=['target']).values
target = df['target']
#------------------------------
model = Sequential()
model.add(Dense(5 #num of hidden units
, input_shape=(data.shape[1],))) #num of features in input layer
model.add(Activation('sigmoid'))
model.add(Dense(1))#number of nodes in output layer
model.add(Activation('sigmoid'))
model.compile(loss='mse', optimizer=keras.optimizers.Adam())
#------------------------------
model.fit(data, target, epochs = 5000, verbose = 1)
model.save("model_for_%s.hdf5" % index)
#------------------------------
#finally, close sessions
session.close()
keras.backend.clear_session()
return 0
#-----------------------------
#main program
multiprocessing.set_start_method('spawn', force=True)
df = pd.read_csv("dataset.csv")
my_tuple = [(i, df[df['index'] == i]) for i in range(0, 100)]
threads = 10
cycles = int(len(my_tuple) / threads)
cycle_idx = 0
for i in range(0, cycles):
with Pool(threads) as pool:
pool.starmap(train, my_tuple[cycle_idx * threads: cycle_idx * threads + threads])
#we might run garbage collector here
cycle_idx = cycle_idx + 1
Notice that we set GPU configuration in sub program – train. If we want to limit the number of cpu cores, then it should be coded here as well.
I pushed the code for GPU enabled multiprocessing task to GitHub.
Using all GPUs
This case might be seen as the simplest but it is not. Having multiple GPUs won’t make you a couple times faster or stronger. Gradients and computations must be stored same GPU. Herein, nvlink would fasten you but still it does not make you number of GPUs times faster. Besides, horovod can be a choice here. It is developed by Uber engineers. It combines separate GPUs virtually.
So, I’ve shared some tips and tricks for GPU and multiprocessing in TensorFlow and Keras I experienced in time. I can reduce the time for prediction task from 3.3 hours to 4 minute for a case. Fasten almost 50 times. Similarly, time for training task reduced from 25 hours to 1 hour. It is amazing, right? You can just run the watch nvidia-smi command, monitor and have fun!
Support this blog financially if you do like!



Also would you be able to share code for tensorflow v2?